实验数据:adult.data
编译环境:pycharm
代码编写:Sublime Text3
import pandas as pd #加载数据 df = pd.read_csv( '.\\adult.data' )#请将adult.data和当前.py放在同一文件目录之下 print(df)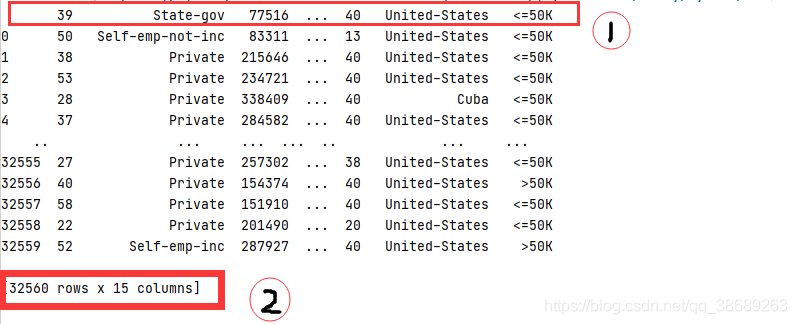
由于在pd.read_csv( '.\\adult.data' ) 里面的参数,并没有指明header=None,默认就将数据第一行当作数据头了。
import pandas as pd #加载数据 df = pd.read_csv( '.\\adult.data',header=None) print(df)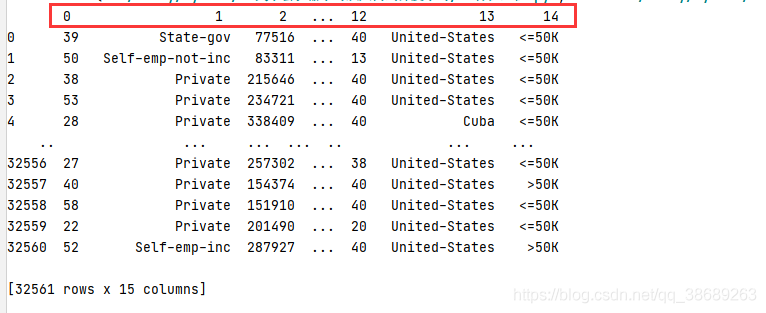
header=None
③增加表头说明
import pandas as pd names = ['age', 'workclass', 'fnlwgt', 'education', 'educationnum', 'maritalstatus', 'occupation', 'relationship', 'race','sex', 'capitalgain', 'capitalloss', 'hoursperweek', 'nativecountry', 'label'] #加载数据 df = pd.read_csv( '.\\adult.data',header=None, names=names) print(df)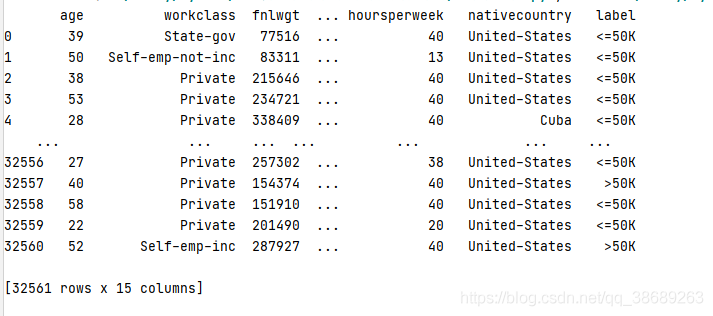
④保存文件
#预测年收入是否大于50K美元 import pandas as pd names = ['age', 'workclass', 'final_weight', 'education', 'education_num', 'marital_status', 'occupation', 'relationship', 'race','sex', 'capital_gain', 'capital_loss', 'hours_per_week', 'native_country', 'salary'] #加载数据 df = pd.read_csv( '.\\adult.data',header=None, names=names)#原资料adult.data没有头,现在names加上 df.to_csv("adults.csv",index=0)##不保存行索引上一个:希尔排序(Java语言实现)
热门文章
- 猫咪打的三针疫苗多少钱啊图片(猫咪打的三针疫苗多少钱啊图片大全)
- Go1.18 新特性之多模块Multi-Module工作区模式_Golang
- PHP匿名类
- Docker基础数据卷容器的说明与共享数据原理详解
- 天宠宠物医院怎么样啊(天宠官网)
- 「1月11日」最高速度22.5M/S,2025年Clash/V2ray/Shadowrocket/SSR每天更新免费节点订阅链接
- 猫的体内驱虫多久一次(猫的体内驱虫多久一次好)
- EFCore 的 DbFirst 模式
- 「2月26日」最高速度19.4M/S,2025年Shadowrocket/Clash/V2ray/SSR每天更新免费节点订阅链接
- 动物疫苗新法案解读最新版(动物疫苗立法)